Get ahead
VMware offers training and certification to turbo-charge your progress.
Learn moreThe Spring Cloud Data Flow team is pleased to announce the release of 1.7.0. Follow the Getting Started guides for Local Server, Cloud Foundry, and Kubernetes. Look for an updated Cloud Foundry Tile for SCDF release in the coming weeks.
Improved UI
Stream Application DSL
Audit trail
Concurrent Task Launch Limiting
Stream and Task validation
Force upgrade for Streams
Task Scheduling on Kubernetes
The UI has a completely new look. The navigation has moved from tabs to a left side navigation system. This gives increased screen real estate for creating streams with the Flo designer and even more screen real estate can be obtained by minimizing the left side navigation. There is a quick search feature that searches across all the different Data Flow categories. Additional colors and overall theme changes have been added to make the UI look more lively. Deeper in the core, the route management has been improved and we have increased our end to end testing coverage using BrowserStack/SauceLabs. The property whitelisting functionality has been refined to not display all application properties by default if the whitelist is empty. Check out the video for a UI walkthough.
Not all use cases can be solved by having a linear pipeline with data flowing from source to processor to sink with a single destination connecting each application. Some use cases require a collection of applications that have multiple input and outputs. This topology is supported in Spring Cloud Stream by using user defined binding interfaces but was not supported in Data Flow. It is also common to have multiple inputs and outputs in Kafka Streams applications.
In addition, not all use cases are solved using Spring Cloud Stream applications. A http gateway application that sends a synchronous request/reply message to a Kafka or RabbitMQ application can be written using only Spring Integration.
In these cases, Data Flow can’t make assumptions about the flow of data from one application to another and therefore can’t set the application’s destination properties as is done when using the Stream Pipeline DSL.
To address these use cases we have introduced the Stream Application DSL. This DSL uses a comma, instead of the pipe symbol, to indicate that Data Flow should not configure the binding properties of the application. Instead, the developer needs to set the appropriate deployment properties to 'wire up' the application. An example of the DSL using the domain of the EIP Cafe example, is
dataflow:> stream create --definition "orderGeneratorApp, baristaApp, hotDrinkApp, coldDrinkApp" --name myCafeStream
Where the listed applications in the DSL need to be registered as --type app.
In this stream, the baristaApp has two output destinations intended to be consumed by the hotDrinkApp and coldDrinkApp respectively. When deploying the stream, set the destination properties such that destinations match up for the desired flow of data, for example:
app.baristaApp.spring.cloud.stream.bindings.hotDrinks.destination=hotDrinksDest app.baristaApp.spring.cloud.stream.bindings.coldDrinks.destination=coldDrinksDest app.hotDrinkApp.spring.cloud.stream.bindings.input.destination=hotDrinksDest app.coldDrinkApp.spring.cloud.stream.bindings.input.destination=coldDrinksDest
Here is a video showcasing this functionality.
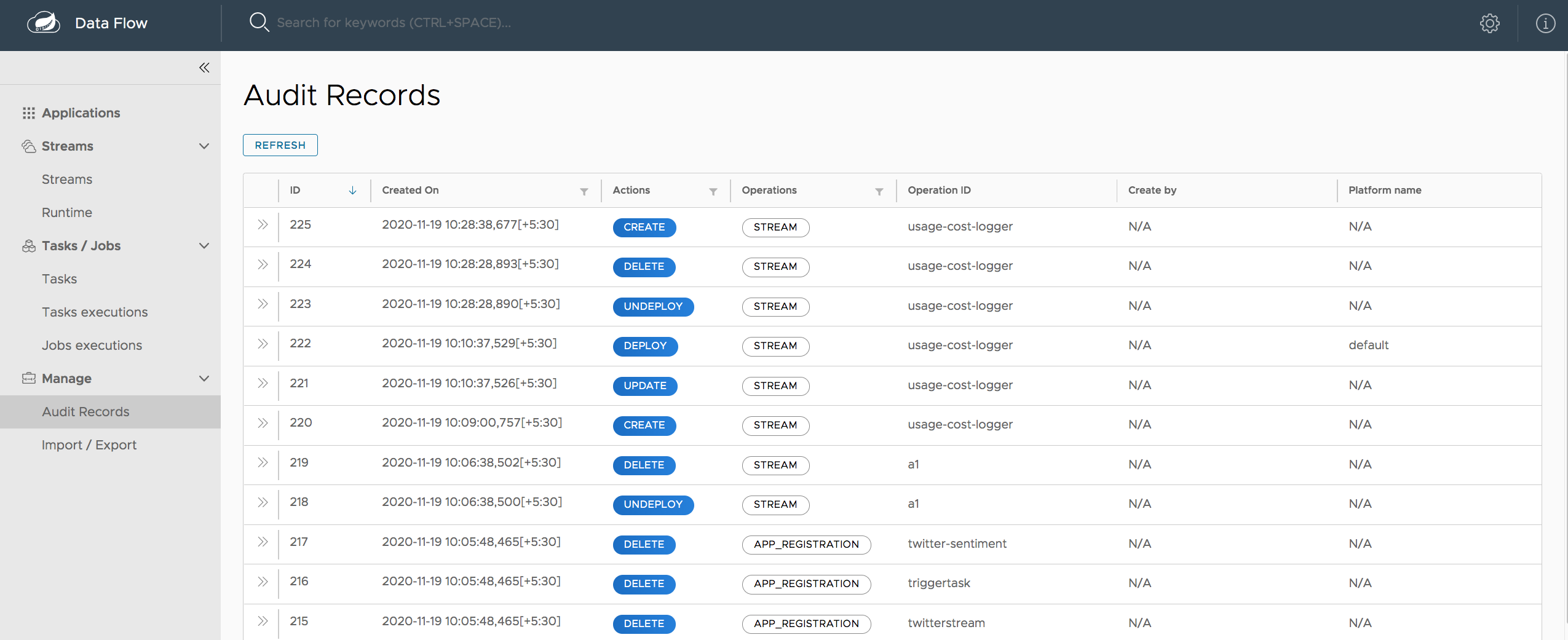
To help answer the question "Who did what and when?" an audit trail has been introduced to store the actions taken involving schedules, streams and tasks. For apps and schedules the create and deletion actions are audited. For streams, the creation, deletion, deployment, undeployment, update and rollback are audited. For tasks, the creation, launching and destory are audited. The audit information is available in the UI to query. Accessing audit information in the shell is forthcoming.
Spring Cloud Data Flow allows you to enforce a maximum number of concurrently running tasks to prevent the saturation of compute resources. This limit can be configured by setting the spring.cloud.dataflow.task.maximum-concurrent-tasks property. The default value is 20. You can also retrieve the current number of concurrently executing tasks though the REST endpoint /tasks/executions/current. A new tasklauncher-dataflow application makes use of this feature to only launch tasks if the number of concurrent tasks is below the maximum. The feature is also at the center of a new FTP ingest sample application that is under development. A sneak peak is available in the Cloud-native patterns for Data-intensive applications webinar
The new shell commands stream validate and task validate will validate that the stream or task application resources are valid and accessable. This avoids getting exceptions at deployment time. Validation using the UI is forthcoming.
Use the force! When upgrading a stream, you can now use the option --force to deploy new instances of currently deployed applications even if no applicaton or deployment properties have changed. This behavior is needed in the case when configuration information is obtained by the application itself at startup time, for example from Spring Cloud Config Server. You can specify which applications to force upgrade by using the option --app-names. If you do not specify any application names, all the applications will be force upgraded. You can specify --force and --app-names options together with --properties or --propertiesFile options.
Task Scheduling was introduced in Data Flow 1.6 for Cloud Foundry. This release adds scheduling support for scheduling of tasks on Kubernetes.
The 1.7 release will be the last minor release in the 1.x series. We will be moving onto development of 2.0 which will remove the 'classic' mode and upgrade to a Boot 2.1 based stack. Other features are planned as well, so stay tuned. In the meantime, expect some blog posts discussing using SCDF for FTP file ingest, interopability with Python, and application composition based on Spring Cloud Function.
As always, we welcome feedback and contributions, so please reach out to us on Stackoverflow or GitHub or via Gitter.

VMware offers training and certification to turbo-charge your progress.
Learn moreTanzu Spring offers support and binaries for OpenJDK™, Spring, and Apache Tomcat® in one simple subscription.
Learn moreCheck out all the upcoming events in the Spring community.
View all