Get ahead
VMware offers training and certification to turbo-charge your progress.
Learn moreOn behalf of the team, I’m excited to announce the 1.0 GA release of Spring Cloud Data Flow!
Note
A great way to start using this new release is to follow the Getting Started section of the reference documentation. It uses a Data Flow server that runs on your computer and deploys a new process for each application.
Spring Cloud Data Flow (SCDF) is an orchestration service for data microservices on modern runtimes. SCDF lets you describe data pipelines that can either be composed of long lived streaming applications or short lived task applications and then deploys these to platform runtimes that you may already be using today, such as Cloud Foundry, Apache YARN, Apache Mesos, and Kubernetes. We provide a wide range of stream and task applications so you can get started right away to develop solutions for use-cases such as data ingestion, real-time analytics and data import/export.
Streams are defined using a DSL inspired by the Unix pipeline syntax. As an example, the DSL for a stream that performs data ingestion from an http endpoint and writes to an Apache Cassandra database is defined as http | cassandra. In turn each element of this DSL maps onto a Spring Boot microservice application focused on data processing that uses the Spring Cloud Stream programming model. This programming model lets you focus on handling the input and outputs of your applications while SCDF configures how those outputs and inputs map onto the messaging middleware, which is how applications communicate. Multiple message brokers are supported through a binder abstraction in Spring Cloud Stream. Currently RabbitMQ and Kafka are available for use in production. Consumer Groups and Data Partitioning are also supported in Spring Cloud Stream and can be configured when deploying a stream.
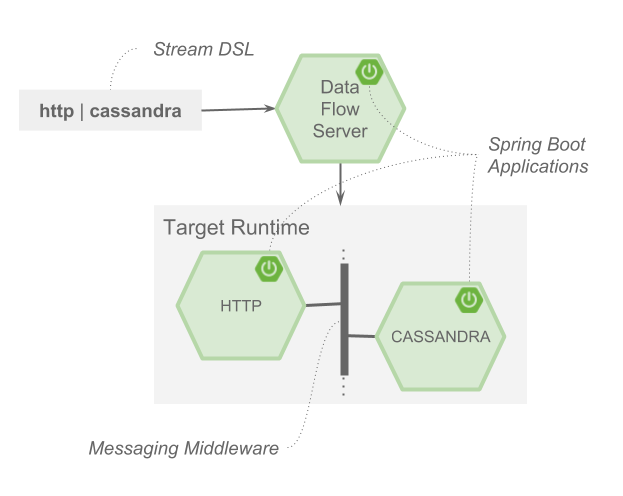
It is very cool how the Unix philosophy of “Write programs that do one thing and do it well.”, “Write programs to work together.”, and “Write programs to handle text streams, because that is a universal interface.” comes together with the microservice architecture and Spring Cloud Stream binders in SCDF.
Today we are also announcing the release of
Spring Cloud Data Flow’s Apache YARN Server 1.0 GA
Spring Cloud Data Flow’s Kubernetes Server 1.0 GA
Spring Cloud Data Flow’s Cloud Foundry Server 1.0 M4
Support for Apache Mesos is under development. We are also quite happy to see community contributions for other runtimes, for example OpenShift. You can find out more about the architecture of SCDF in our reference manual.
Notable features in this release are:
A Stream DSL that describes a data pipeline as a directed graph of individual applications.
DSL support for named destinations that lets you consume events from any ‘pipe’ in the stream definition. This is referred to as tapping a stream. You can also combine the output from multiple streams.
A deployment manifest that lets you define the resource usage of individual applications (CPU, Disk, Memory) as well as application instance count and how to partition data. You can also pass arbitrary application properties when deploying.
Support application packaging as either a Spring Boot uber-jar or Docker image.
Support deploying data microservices built using Spring Cloud Stream for long lived Stream applications that process an unbounded amount of data and Spring Cloud task for applications that process a finite set of data and then terminate. In turn these build upon Spring Boot.
A shell application with tab-completion to create, deploy and monitor streams and tasks.
A HTML5 Dashboard that lets you create, deploy, and monitor deployed streams and tasks.
Flo for Spring Cloud Data Flow: A visual designer for Stream definitions that also supports a scriptable-transform processor that accepts Ruby, Groovy, Python, or Javascript code for runtime compute logic.
Support for basic HTTP and OAuth 2.0 authentication.
‘NoSql’ style real-time analytics using Field Value and Aggregate Counters with HTTP endpoints on the server to access counter values. Counter data is backed by Redis.
Use Spring Initializr to simplify the creation of stream applications.
Spring Cloud Stream applications support RabbitMQ and Kafka 0.8
Task and Stream Application Starters that you can use to customize the many source, processor, sink and task applications that we have provided.
Whitelisting of Spring Boot application properties gives the shell/UI information to show a preferred set of boot properties to display for code completion and application info.
Spring Cloud Data Flow has been under development for about one year, having evolved out of the previous project Spring XD which had a similar goal, to simplify the development of streaming and batch applications. We learned a great deal through that experience, which has been described quite nicely by Sabby Anandan in this blog post.
A major architectural change was replacing our own application runtime with a pluggable Deployer Service Provider Interface. While much of the engineering time spent in Spring Cloud Data Flow 1.0 GA was in making this architectural shift, we are now in a very good position to continue to add higher level value on top of this foundation and not have to spend time developing core runtime features. Here are some of the ideas on the team’s collective mind:
By depending on the components of a stream or task application to be ‘just apps’, we can take advantage of many other Spring Cloud projects, such as Spring Cloud Sleuth to collect response times in a distributed application.
Integration with Spinnaker to handle the responsibilities of continuous deployment/upgrading of applications since Spinnaker ‘deals with apps’ as its unit of currency and can use data such as response times in making automated decisions to upgrade to new versions of an application.
Polyglot deployment, we want to deploy more than Java Spring Boot apps. We will be looking first into deploying Python apps, since many Data Science teams use Python to develop models that need to be evaluated in real-time.
Bring back the Task DSL and UI Designer from Spring XD.
Since Spring Cloud Data Flow is decoupled from the release lifecycle of Spring Cloud Stream and Spring Cloud Task, as those projects release new features, they can immediately be consumed by SCDF. Some of the exciting features for Spring Cloud Stream worth mentioning are support for Project Reactor and Kafka Streams APIs as well as binding support for Kafka 0.9, Google Cloud Pub/Sub, Azure Event Hubs, and JMS. For Spring Cloud Task, there are plans to support the latest Task features on Cloud Foundry. Check out the roadmaps for those two projects for details
For the complete list of features, bug-fixes, and improvements, please refer to the closed 1.0 RELEASE GitHub issues.
We welcome feedback and contributions! If you have any questions, comments or suggestions, please let us know via GitHub Issues, StackOverflow, or using the #SpringCloudDataFlow hashtag on Twitter.
SpringOne Platform is right around the corner. In addition to several sessions covering Spring Cloud Data Flow and dependent projects, there will also be a two day training class. The entire Spring Cloud Data Flow team will be there, looking forward to seeing you there!

VMware offers training and certification to turbo-charge your progress.
Learn moreTanzu Spring offers support and binaries for OpenJDK™, Spring, and Apache Tomcat® in one simple subscription.
Learn moreCheck out all the upcoming events in the Spring community.
View all